Organizing documents to support browsing in digital libraries
Yoelle S. Maarek
Research Staff Member
IBM Haifa Research Lab
Haifa 31905, ISRAEL
ph: +972-4-296-336
FAX: +972-4-296-114
yoelle@haifa.vnet.ibm.com
Motivation
With the advent of digital libraries and of wide area networks,
enormous amounts of textual information are made available all over
the world: A typical example being the World Wide Web on the Internet.
Searching and browsing are the two resource discovery paradigms mostly
used to access this information [Bowman
94]. Information retrieval
(IR) provides numerous sophisticated automatic indexing and storing
techniques to support efficient searching and retrieval. In contrast,
the organizing process that makes browsing possible, is typically done
manually. The advances in automatic techniques for supporting the
browsing discovery paradigms does not compare to those that support
searching, in spite of the fact that browsing is classically the first
paradigm used before searching.
The issue we would like to address at the Institute is the issue of
document organization which seems to have been neglected by the
research community. This relates to the proposed issue of discussion:
"What do we need to know about how people use electronic texts and how
can we gain this knowledge and apply it to the development of digital
libraries?" We would like to discuss organization by content as well
as by other criteria such as fixed fields (author?, subject?, date?,
etc.).
Our current research work in this direction
We have devised a tool: "the Librarian's Assistant" [Maarek 94] whose
goal is to provide assistance in organizing sets of documents by
contents. It takes as input an unstructured set of textual objects
(e.g., books, documents, etc.) and automatically generates a hierarchy
of document clusters with which the user can interact.
Document clustering has been for long an area of interest in IR
[Voorhees 86], [Willett
88] but has been primarily
used for improving
the effectiveness and efficiency of the retrieval process, [Rasmussen 92]. We are more concerned here
with the
primary use of cluster
analysis which is the visualization of underlying structures for
explanatory purposes. Since the hierarchy is going to be shown to the
user, and not simply used internally by the retrieval engine, it has
to be more precise.
The clustering process is based upon pairwise similarity between
documents which is itself inferred from a profile of representative
indices for each document. We use multiple-word indices that represent
lexical affinities and thus get a richer and more precise indexing
unit than single words as has been described elsewhere [Maarek 89].
The Librarian's Assistant identifies underlying structures in
collections of documents. These structures are visualized via a hierarchy
of folders or clusters, each cluster gathering documents conceptually
similar. The user can interact with the structure via a graphical
user interface in order to obtain for each cluster a list of key
concepts as well as an automatically generated title that allows to
understand what the cluster is about.
The Librarian's Assistant: applications
The applications of the Librarian's Assistant technology are multiple.
In the context of the World Wide Web, it can be used to organize
either publisher information on a given Web server (e.g. home pages
and sub-webs) or personal information that has been collected on the
Web (See Figure 1: organization of man pages
below). In the context of a search
system, it can be used to provide an orthogonal view to search
results, for instance identify groups of documents answering a
specific query rather than single documents (See Figure 2: organizing search results via
clustering in Guru below), as well as to restrict
the scope of a search to a sub-domain. In the context of document
management systems in general, the Librarian's Assistant can be used
to automatically place related documents in a same folder, and to
organize the generated folders.
Examples
Automatic organization of man pages
In this example, an administrator has requested
the Librarian's Assistant to cluster about 100 man pages of
the AIX commands (IBM's Unix), by default
is associated with every cluster an
"intra-cluster similarity" percentage indicating how similar the
documents within that cluster are (100 %= conceptually identical,
0%=conceptually independent).
A portion of the HTML output (Web interface of the tool) is included below.
Note the hotbuttons links from documents to source are not enforced
here. The full-fledged Web interface also allows to get a title and
list of key concepts for clusters by clicking on the folder icon (not
provided here).
....
 [ 26%] contains 4 documents
[ 26%] contains 4 documents
- [ 48%]contains 2 documents
 piobe.cmd
piobe.cmd
- qprt.cmd
- [ 40%] contains 2 documents
- pioburst.cmd
- pioout.cmd
- [ 26%] contains 2 documents
- bugfiler.cmd
- sendbug.cmd
- [ 26%] contains 2 documents
- bc.cmd
- dc.cmd
- [ 25%] contains 7 documents
- comb.cmd
- [ 49%] contains 2 documents
- cdc.cmd
- delta.cmd
- [ 36%] contains 4 documents
- sccsdiff.cmd
- sccshelp.cmd
- [ 50%] contains 2 documents
- rmdel.cmd
- sact.cmd
...
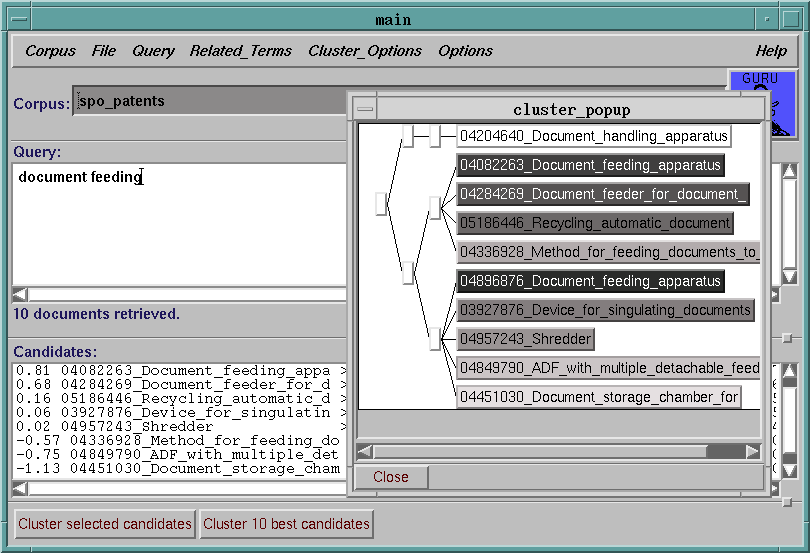
Clustering of search results
The example below, show a retrieval session in which he user queries a
collection of patent abstracts and clusters the top ten candidates in
order to understand why two abstracts with similar titles (but
different patent IDs) get sich different scores.
By clustering the user notices that the top two candidates belong to
two different clusters, which means that they must be drastically
different. By examining sample documents from each cluster, the user
discovers that his/her query was not precise enough and that one top
candidate talks about feeding physical documents (in the context of
copying machine) whereas the second talks obout online documents.
The clustering process allows to discover these ambiguity in the query
as it identified on cluster for physical documents and one for online
documents. The user then does not need to reissue a more precise query
to filter out the kind of documents s/he not interested in, but needs
only to look at the cluster relevant to him/her.
In summary, whenever collections of documents are available, the
Librarian's Assistant allows to provide the organization needed to
browse and search or simply to get a global understanding of the
structure of a collection. A Motif interface on Unix and a PM
interface on OS/2 are available as well as a custom-made version for
the World Wide Web.
References:
Bowman, C.M., Danzig, P.B., Manber, U., and Schwartz, M.F.
Scalable internet: Resource discovery.
Communications of the ACM 37, 8 (August 1994).
Maarek, Y., and Smadja, F.
Full text indexing based on lexical relations. an application:
Software libraries.
In Proceedings of SIGIR'89 (Cambridge, MA, June 1989),
N.Belkin and C.van Rijsbergen, Eds., ACM Press, pp.198--206.
Maarek, Y., and Wecker, A.
The librarian's assistant: Automatically assembling books into
dynamic bookshelves.
In Proceedings of RIAO'94, Intelligent Multimedia, Information
Retrieval Systems and Management (NY, NY, October 1994).
Rasmussen, E.
Information Retrieval, Data Structure and Algorithms.
Prentice Hall, 1992, ch.16, Clustering Algorithms, pp.419--442.
Voorhees, E.
The Effectiveness and Efficiency of Agglomerative Hierarchic
Clustering in Document Retrieval.
PhD thesis, Cornell University, 1986.
Willett, P.
Recent trends in hierarchic document clustering: a critical review.
Information Processing & Management 24, 5 (1988), 577--597.